포털 검색에 대한 기본적인 개념
검색은 아마 인터넷 초기 부터 생겨난 주요 서비스이다.
과거에는 방대한 데이터를 검색할 용도로 사용되었는데..
이제는 포털의 핵심 매출원이 되었다.
(2년전에도 이미 라디오 광고는 넘어섰다고 한다)
그럼 웹검색의 흐름을 파악해보자..
까치네 - 웹로봇*을 이용한 사이트 검색(키워드매칭)
야후 디렉토리 검색 - 운영자가 카테고리별로 사이트들을 정리한 후에 사이트 검색 지원(키워드매칭)
엠파스 자연어 검색 - 국내 최초로 자연어 검색 및 검색모델(벡터스페이스*)을 적용한 검색 지원
구글 웹 검색 - 웹로봇과 페이지랭킹* 알고리즘으로 웹사이트 검색 지원
네이버 지식in 검색 - 사용자 참여로 지식을 구축해서 만든 검색
웹로봇* :
프로그램이 웹사이트 링크를 따라 돌아다니면서 웹페이지를 수집한다..
벡터스페이스* :
문서 내에 단어에 대한 가중치를 매기는 알고리즘으로
특징은 문서 내에 해당 단어의 비중이 너무 많거나 너무 적으면 가중치를 낮게 준다.
(즉 보편적인 단어들은 가중치가 내려가는 효과)
페이지랭킹* :
웹페이지들 간의 가중치 계산 알고리즘으로
어떤 특정 페이지를 바라보는 링크들의 개수로 가중치를 매긴다.
가령 푸딩코딩맨 이란 사이트를 찾는다면
아마 전세계 페이지에서 푸딩코딩맨이라는 제목으로 링크가 걸린 사이트는
이 블로그일 가능성이 높다는 생각
프로그램이 웹사이트 링크를 따라 돌아다니면서 웹페이지를 수집한다..
벡터스페이스* :
문서 내에 단어에 대한 가중치를 매기는 알고리즘으로
특징은 문서 내에 해당 단어의 비중이 너무 많거나 너무 적으면 가중치를 낮게 준다.
(즉 보편적인 단어들은 가중치가 내려가는 효과)
페이지랭킹* :
웹페이지들 간의 가중치 계산 알고리즘으로
어떤 특정 페이지를 바라보는 링크들의 개수로 가중치를 매긴다.
가령 푸딩코딩맨 이란 사이트를 찾는다면
아마 전세계 페이지에서 푸딩코딩맨이라는 제목으로 링크가 걸린 사이트는
이 블로그일 가능성이 높다는 생각
까치네, 엠파스, 구글의 경우는 프로그램에 의해 대부분 자동적으로 처리했다면
야후, 네이버의 경우는 사람의 손을 거쳐서 나온 검색이라 할 수 있다..
(지금은 대부분 상호 좋은 부분을 취합해서 적용한다..자동이건 수동이건 간에..)
가끔 사람들이 검색 품질을 가지고 구글, 네이버, 엠파스를 비교하는데..
개인적인 입장은 위에 나온 시대 순으로 품질이 좋다고 할 수 있다..
그것은 검색엔진 성능이나 알고리즘은 대부분의 업체가 근소한 차이는 있을지 모르지만
사용자가 느낄 정도의 차이는 극히 미미한 수준이고..
요즘은 얼마나 지식콘텐츠 구성을 잘했느냐의 싸움이기 때문이다..
지식in 이전 검색까지만 해도 구글의 페이지랭킹 알고리즘은 정말 획기적인 발상이었다..
기존의 검색은 웹페이지 가중치를 해당 웹페이지의 글자들만 가지고 따졌는데..
바라보는 링크의 개수를 가지고 가중치를 주면서 웹페이지에 대한 사용자 만족도가
혁신적으로 향상할 수 있었다..
그러나 이것은 링크로 연결된 웹페이지에서만 의미가 있다는 한계점이 있다..
지식in 처럼 잘 구축된 그리고 계속 구축되고 있는 지식콘텐츠와는 차원이 다른 싸움인 것이다..
대부분의 사용자는 네이버에서 검색해서 못찾을 경우 구글에서 검색할 것이다..
요즘은 지식in보다 블로그 검색을 주로 많이 보는데..
아마 블로그 검색도 구글처럼 좀 획기적인 발상을 하면 좋은 검색이 나오지 않을까 하는 생각이 든다..
벡터스페이스
2012년 현재의 시대에 정보검색의 방법으로 학계나 현업에서 인정받는 기술은 바로 구글의 페이지랭크 알고리즘이다. 때문에 사람들은 구글의 페이지랭크가 검색엔진 결과에 대한 랭킹을 가장 잘 표현하는 것으로 생각하기 쉽지만 어떻게 보면 그것 자체가 가장 큰 맹신일 지도 모른다. 때문에 많은 사람들이 검색쿼리 이면의 뜻을 알기 위해 노력하고 있고 그 문맥을 찾아내는 시맨틱 검색을 비롯한 3세대 검색기술이 점차 발전되고 있다.
물론 새로운 기술이 도입되었다 하더라고 기술이라는 것은 항상 완벽한 것은 아니고 어제가 있었기 때문에 오늘이 있었다는 사실을 간과해서는 안된다. 특히 검색엔진 기술에 있어서 벡터 스페이스 모델(Vector Space Model)은 지금도 대부분 검색엔진에서 사용하고 있는 기술이라는 점에서 구시대의 기술이라고 치부할 수 없는 우수한 기술이 되겠다.
- 벡터 스페이스(Vector Space Model)은 말그대로 검색쿼리로 입력된 단어들을 웹페이지에서 찾아 벡터 형태로 배열을 구성하여 점수를 구성하는 것이다. 점수를 구성하는 방법은 TF-IDF(Term Frequency - Inverted Document Frequency)이다. http://en.wikipedia.org/wiki/Vector_space_model
- TF-IDF(Term Frequency - Inverted Document Frequency)를 구할 때는 단어 뜻대로 웹페이지에서 검색쿼리 단어의 빈도의 수와 전체 웹페이지에서의 단어의 빈도수(계산방식은 여러가지임)의 곱의 값(w)를 이용하여 코싸인 유사도를 계산하여 그 값을 통해서 쿼리에 대한 코싸인 유사도와 다큐멘트에 대한 코싸인 유사도를 비교하여 쿼리에 대하여 값이 근사한 다큐멘트 순으로 검색결과를 출력한다. http://en.wikipedia.org/wiki/Tf*idf
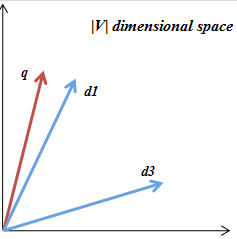
- 코싸인 유사도(Cosine Similirity)는 일반적으로 두 벡터의 각도의 코싸인값을 측정하여 두 벡터의 유사도를 측정하는 방법이다. 예를들어 위 그림에서 q의 벡터값과 d1, d3의 벡터값을 기준으로 q에 가까운 순으로 검색결과를 출력하게 된다. 코싸인 유사도는 일반수학에서 벡터의 내적을 구하는 것과 같다. http://en.wikipedia.org/wiki/Cosine_similarity
겉으로보면 벡터 등이 출현하여 마치 어려운 수학 같지만 실질적 내용은 그렇게 어려운 내용은 아니다. 중요한 것은 이러한 내용을 어떻게 생각해냈느냐 이다. 굳이 수학이 들어가지 않아도 좋다. 모두가 수긍하고 납득할 만한 내용이기만 해도 된다. 이것은 비단 과학 뿐만이 아니라 다른 모든 분야도 마찬가지다. 사람들을 편리하게 하거나 나만의 철학으로 무장하여 무언가 창조적인 것을 만들어내는 것이다.
참조 :
http://socialcomputinglab.blogspot.kr/2012/06/vector-space-model-tf-idf-weight.html